Last active
June 30, 2022 17:13
-
-
Save Minecraftian14/718ad6c5460fb3287509c32d6fef1bcd to your computer and use it in GitHub Desktop.
Implementing basic convolution algorithms in python.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| from keras.datasets import mnist | |
| from CyDifferentTypesOfLayers import * | |
| class ConvolutionLayer(LayerChain): | |
| def __init__(this, s_in: DimsND, filter_size: int, lr: float): | |
| this.conv = ConvolutiveParametersLayer(s_in, lr, (filter_size, filter_size)); | |
| this.bias = AdditiveParametersLayer(this.conv.s_out, this.conv.s_out, lr); | |
| super().__init__([this.conv, this.bias], lr); | |
| this.f = this.conv.f; | |
| this.b = this.bias.b; | |
| def predict(this, a_in: ndarray) -> ndarray: | |
| a_out = super().predict(a_in); | |
| return a_out; | |
| def forward(this, a_in: ndarray) -> ndarray: | |
| a_out = super().forward(a_in); | |
| this.a_in = this.conv.a_in; | |
| return a_out; | |
| if __name__ == '__main__': | |
| train_X: ndarray; | |
| train_y: ndarray; | |
| test_X: ndarray; | |
| test_y: ndarray; | |
| (train_X, train_y), (test_X, test_y) = mnist.load_data(); | |
| train_X = normalizeData(train_X.astype(float)); | |
| test_X = normalizeData(test_X.astype(float)); | |
| train_y = one_hot_encode(train_y); | |
| test_y = one_hot_encode(test_y); | |
| print(train_X.shape[0], test_X.shape[0]); | |
| train_X = train_X[:1000, :, :]; | |
| train_y = train_y[:1000, :]; | |
| test_X = test_X[:1000, :, :]; | |
| test_y = test_y[:1000, :]; | |
| print(*np.sum(train_y, axis=0)) | |
| print(*np.sum(test_y, axis=0)) | |
| print(train_X.shape[0], test_X.shape[0]); | |
| n = train_X.shape[2]; | |
| c = train_y.shape[1]; | |
| lr = 0.00001; | |
| train_X = train_X.reshape(train_X.shape + (1,)); | |
| test_X = test_X.reshape(test_X.shape + (1,)); | |
| # train_X = get_windows_for_mini_batch(train_X, size_of_batches=600); | |
| # train_y = get_windows_for_mini_batch(train_y, size_of_batches=600); | |
| grabber = LayerGrabber(); | |
| def create_model(): | |
| layers = []; | |
| layers.append(InputLayer((n, n, 1))); | |
| layers.append(ConvolutionLayer((n, n, 1), 3, lr)); | |
| # layers.append(MaxPoolingLayer((n, n, 1), (2, 2), lr)); | |
| layers.append(ReluLayer((n, n, 1), (n, n), lr)); | |
| # layers.append(Flatten((n, n, 1), n * n, lr)); | |
| # layers.append(ConvolutiveParametersLayer(layers[-1], lr, (3, 3), 3, striding=(2, 2))); | |
| # layers.append(ReluLayer(layers[-1])); | |
| # layers.append(ConvolutiveParametersLayer(layers[-1], lr, (3, 3), 3, striding=(2, 2))); | |
| # layers.append(DeprecatedMaxPoolingLayer(layers[-1], (2, 2, 1))); | |
| # layers.append(AdditiveParametersLayer(layers[-1], lr)); | |
| # layers.append(ReluLayer(layers[-1])); | |
| # layers.append(AdditiveParametersLayer(layers[-1], lr)); | |
| # layers.append(ConvolutionLayer(layers[-1], 3, lr)); | |
| # layers.append(MaxPoolingLayer(layers[-1], (2, 2), lr)); | |
| # layers.append(ReluLayer(layers[-1], layers[-1], lr)); | |
| layers.append(Flatten(layers[-1])); | |
| # layers.append(SuperMultiplicativeParametersLayer(layers[-1], lr, 2)); | |
| layers.append(Perceptron(layers[-1], 2, lr)); | |
| layers.append(TanHLayer(layers[-1])); | |
| # layers.append(Perceptron(layers[-1], 128, lr)); | |
| # layers.append(TanHLayer(layers[-1])); | |
| # layers.append(grabber.grab(Perceptron(layers[-1], 32, lr))); | |
| # layers.append(TanHLayer(layers[-1])); | |
| # layers.append(Perceptron(layers[-1], 32, lr)); | |
| # layers.append(TanHLayer(layers[-1])); | |
| layers.append(Perceptron(layers[-1], 32, lr)); | |
| layers.append(TanHLayer(layers[-1])); | |
| # layers.append(BackDependenceLayer(grabber.layer)); | |
| # layers.append(ResidualNetworkLayer(grabber.layer)); | |
| layers.append(Perceptron(layers[-1], 10, lr)); | |
| layers.append(SigmoidLayer(layers[-1], layers[-1], lr)); | |
| # layers = list(map(lambda l: ClipLayer(l), layers)); | |
| return LayerChain(layers, lr); | |
| model = create_model(); | |
| for l in model.layers: | |
| print(l.__class__, l.s_out); | |
| loss = BCELoss(); | |
| observer_loss = SimpleLoss(); | |
| costRecorder = PlotTestDataToo(test_X, test_y, loss, observer_loss); | |
| trainer = Trainer([ | |
| costRecorder | |
| # , AutomaticDecayingLearningRate(costRecorder, 0.1) | |
| ]); | |
| def ims(m: Layer): | |
| i = np.random.randint(c); | |
| print('using', i); | |
| plt.imshow(m.un_predict(decode(c, i))[0]); | |
| plt.title(i); | |
| plt.show(); | |
| def imc(m: Layer): | |
| beef = []; | |
| while len(beef) != 10: | |
| print("Please enter 10 floats"); | |
| beef = [float(x) for x in input().split(' ')] | |
| plt.imshow(m.un_predict(np.array([beef]))[0]); | |
| plt.title(np.argmax(beef)); | |
| plt.show(); | |
| model = trainer.start_observatory(model, train_X, train_y, | |
| loss, observer_loss, create_model, | |
| bayes_error=0, max_iterations=10, | |
| custom_commands={ | |
| 'cm': lambda m: ConfusionMatrix(test_y, m.forward(test_X)).print_matrix(), | |
| 'cmt': lambda m: ConfusionMatrix(train_y, m.forward(train_X)).print_matrix(), | |
| 'im': lambda m: ims(m), | |
| 'imc': lambda m: imc(m) | |
| }); | |
| test_yp = model.forward(test_X); | |
| print(observer_loss.cost(test_y, test_yp)[0] * 100); | |
| m = ConfusionMatrix(test_y, test_yp); | |
| m.print_matrix(); |
Author
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Results of Training on MNIST-Fashion
(10k train samples and 1k test samples)
Train Set Accuracy = 87.22%
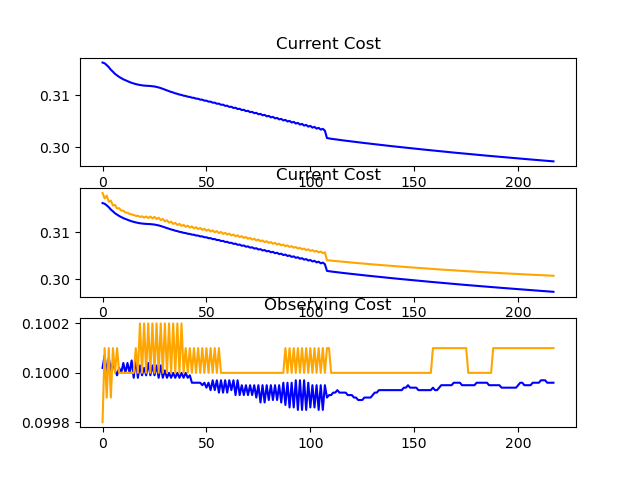
Test Set Accuracy = 82.40%
https://drive.google.com/file/d/1-TJGgfLoub1-ZJ8K0KdCuepc_wXSi1uz/view?usp=sharing
Train Set Accuracy = ~85%
Test Set Accuracy = 83%