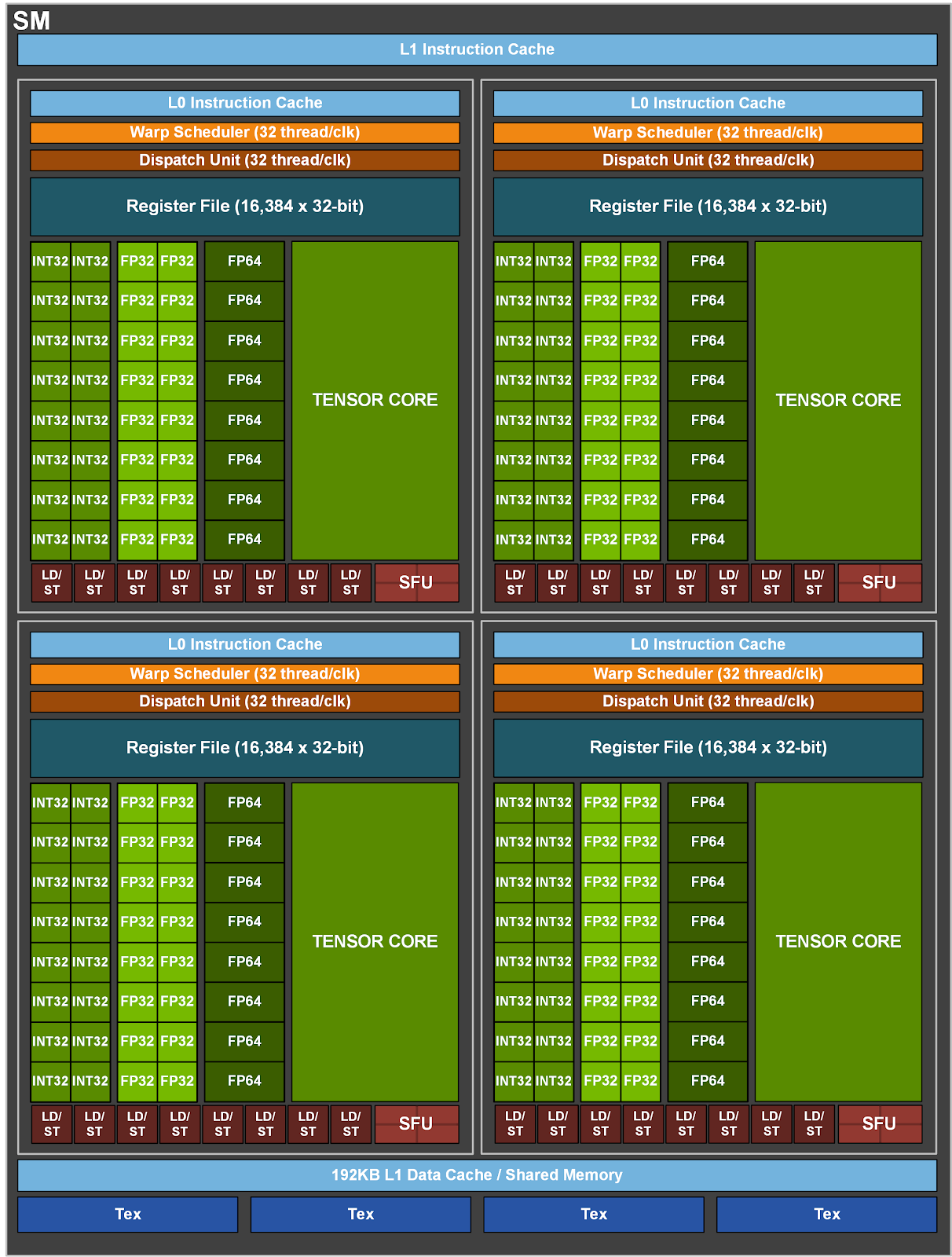
Ampere (GA10x GPU): 6144 KB L2 Cache (12 32-bit memory controllers (384-bit total), 512 KB of L2 cache is paired with each 32-bit memory controller) Each SM: 128 CUDA Cores, 4 3rd-generation Tensor Cores, a 256 KB Register File, 128 KB of L1/Shared Memory. each SM has 4 partitions (a 64 KB Register File, one 3rd-generation Tensor Core, an L0 instruction cache, one warp scheduler, one dispatch unit, and sets of math and other units). The four partitions share a combined 128 KB L1 data cache/shared memory subsystem.
Turing and Volta SMs support concurrent execution of FP32 and INT32 operations
Volta (GV100 GPU): each SM has 4 partitions (6 FP32 Cores, 8 FP64 Cores, 16 INT32 Cores, 2 1st-gen Tensor Cores, , a new L0 instruction cache, one warp scheduler, one dispatch unit, and a 64 KB Register File).
Note that the new L0 instruction cache is now used in each partition to provide higher efficiency than the instruction buffers used in prior NVIDIA GPUs. (See the Volta SM in Figure 5).
Pascal (GP100):
Each SM: 2 partitions (a 128 KB Register File, 32 FP32 Cores, 16 FP64 Cores, an instruction buffer, one warp scheduler, two dispatch units, and )
Tensorcore FLOPS on 3060ti:
f16 and f16 acc: 38 SMs * 4 TCs/SM * 128 (FP16 FMA operations per Tensor Core) * 2* 1410 MHz
38 * 4 * 128 * 2 * 1410 = 54.865920 TFLOPS
f16 and f32 acc: 54.865920 / 2 = 27.4 TFLOPS
f32 and f32 acc: 54.865920 / 4 = 13.7 TFLOPS