6 groups of models inherit from BartForConditionalGeneration.
The major differences between them are:
- pretraining objective & data
- finetuning objective & data
- number of layers and dimension of each layer
- when layernorm is applied
This document focuses on layernorm timing.
Here are the three relevant BartConfig parameters that control which layernorms are instantiated and when they are applied:
| add_final_layer_norm | normalize_embedding | normalize_before | |
|---|---|---|---|
| facebook/bart-large-cnn | False | True | False |
| facebook/mbart-large-en-ro | True | True | True |
| facebook/blenderbot-3B | True | False | True |
| facebook/blenderbot-90M | False | True | False |
| google/pegasus-large | True | False | True |
| Helsinki-NLP/opus-mt-en-de | False | False | False |
For background, LayerNorm tries to normalize inputs using two parameters (called weight and bias) in the following picture:
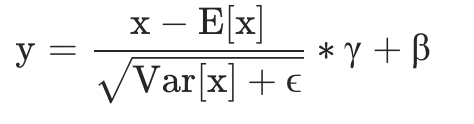
It was introduced in this paper as an alternative to BatchNorm
we transpose batch normalization into layer normalization by computing the mean and variance used for normalization from all of the summed inputs to the neurons in a layer on a single training case. Like batch normalization, we also give each neuron its own adaptive bias and gain which are applied after the normalization but before the non-linearity. Unlike batch normalization, layer normalization performs exactly the same computation at training and test times.
When normalize_before==True, as is the case for blenderbot-3B, mBART and pegasus, we apply layernorms before the associated operation. For blenderbot-90, BART and marian, we apply layernorm after the operation.
Here is some pseudocode for the Encoder to illustrate the difference
Encoder
layernorm_embedding
for each EncoderLayer:
if normalize_before: self_attn_layer_norm
x = self_attention(x)
if not normalize_before: self_attn_layer_norm
if normalize_before: final_layer_norm # final of the layer...
x = x + fully_connected_network(x)
if not normalize_before: final_layernorm
done
if config.add_final_layernorm: layernorm # see belowThe decoder is very similar, with two wrinkles.
First, each DecoderLayer also has cross attention and an associated layernorm, called encoder_attn_layer_norm, for a total of 3 layernorms. The timing of these layernorms, just like in EncoderLayer is controlled by config.normalize_before.
The other difference only pertains to config.do_blenderbot_90_layernorm which is only True for blenderbot-90M.
At the very beginning of the decoder after we compute token embeddings, blenderbot-90 calls its layernorm_embedding.
The other models wait until the positional embeddings are added to the token embeddings. Here is the real code:
x = self.embed_tokens(input_ids) * self.embed_scale
if self.do_blenderbot_90_layernorm:
x = self.layernorm_embedding(x) + positions
else:
x = self.layernorm_embedding(x + positions)self.layernorm_embedding is an Identity operation, not a layernorm for 3/6 models: where config.normalize_embedding=False in the table above.
This is implemented by the following conditional
self.layernorm_embedding = LayerNorm(embed_dim) if config.normalize_embedding else nn.Identity()mBart, pegasus and blenderbot-3B both have an extra layernorm that they apply as the last operation of the encoder and decoder. The other 3 checkpoints don't.
In modeling_bart.py, this difference is implemented by the following conditional:
self.layer_norm = LayerNorm(config.d_model) if config.add_final_layer_norm else nn.Identity()